Development
Retrieval-Augmented Generation (RAG) has become a cornerstone technology for building intelligent, context-aware AI applications. This comprehensive guide explores the architecture, best practices, and implementation patterns for production-ready RAG systems.
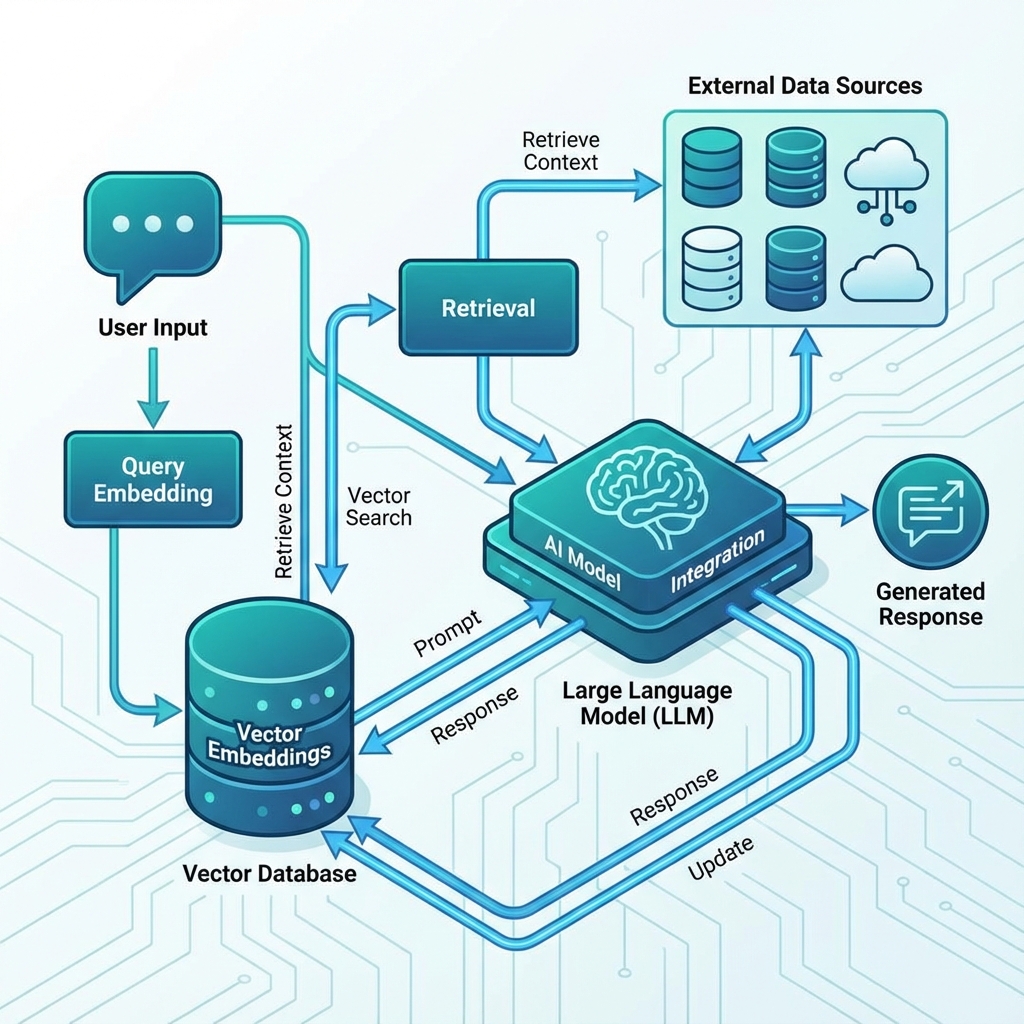
Understanding RAG Architecture
RAG systems combine the power of large language models with external knowledge retrieval, enabling AI to access up-to-date information and domain-specific knowledge without retraining.
Core Components
- Vector Database: Stores embeddings for efficient similarity search
- Embedding Model: Converts text into vector representations
- Retrieval System: Finds relevant context from the knowledge base
- LLM: Generates responses using retrieved context
Best Practices for Production
Building a scalable RAG system requires careful consideration of performance, accuracy, and cost.
1. Optimize Your Embeddings
Choose the right embedding model for your use case. Consider factors like dimensionality, accuracy, and inference speed. Fine-tuning embeddings on domain-specific data can significantly improve retrieval quality.
2. Implement Hybrid Search
Combine vector similarity search with traditional keyword search for better results. This hybrid approach captures both semantic meaning and exact matches.
3. Chunk Your Data Intelligently
The way you split your documents into chunks dramatically affects retrieval quality. Consider semantic boundaries, maintain context, and experiment with chunk sizes.
Scaling Considerations
As your RAG system grows, focus on:
- Caching frequently accessed embeddings
- Implementing efficient indexing strategies
- Load balancing across multiple vector databases
- Monitoring and optimizing query performance
"The key to a successful RAG system is finding the right balance between retrieval accuracy and response latency." - Michael Rodriguez
Conclusion
RAG systems represent a powerful approach to building AI applications that are both knowledgeable and adaptable. By following these best practices and patterns, you can create production-ready systems that deliver accurate, contextual responses at scale.
